Related Systems/Technologies/Research Projects (under construction)
I also maintain a list of programming languages for human computation and crowdsourcing applications.
On data-centric systems, Anhai Doan, Michael Franklin, Donald Kossmann, and Tim Kraska gave a tutorial at VLDB 2011.
- TurKit: A Java/JavaScript API for running iterative tasks on Mechanical Turk. With TurKit, programmers write programs in a straightforward imperative manner, but can safely re-execute programs without re-running costly side effects on Mechanical Turk. CyLog provides a data-centric declarative abstraction, focusing on the fusion of human/machine computations.
- CrowdLang: A model-based programming language for complex crowdsourcing applications.
It is interesting that it provides a set of common patterns and concepts taken from collective intelligence applications.
Currently, it seems that the codes in CrowdLang are written at an abstract level. In contrast, the codes in CyLog is executable.
- Collective Knowledge Bases:
In the project, they constructed a system to leverage mass collaboration to build large knowledge bases. In the system, contributers (1) give facts and rules and (2) receive feedbacks.
The collected knowledge base is utilized in an traditional expert-system fastion.
For example, it is used for printer truble shooting.
In contrast, CyLog is designed for data-centric applications, in which we collect, process, integrate, and manage data in the presence of human data sources.
This makes a big difference in the language design.
For example, CyLog does not take the traditional closed world assumption and has a mechanism to solicit human input.
- Qurk:
Qurk helps users build crowd-powered data processing workflows using a SQL-like language.
In Qurk, user-defined functions are incorporated into SQL queries to interact with the crowd.
In contrast, CyLog programs employ Datalog-style rules and an event-driven semantics.
- sCOOP: The Stanford--Santa-Cruz Project for Cooperative Computing with Algorithms, Data and People. Their hQuery is discussed in a Datalog-like notation. The h/ha-predicates of hQuery and our open predicates have some similarity. An open predicate is evaluated by humans when it cannot be evaluated by machines (through data or algorithms), while h-predicates and ha-predicates are evaluated by humans and both of human and algorithms, respectively.
It is interesting that they have different (and possibly complementary) approaches to deal with data values obtained by people.
hQuery takes the crowd-as-a-data-source approach, in that each value (associated with its certainty) is automatically by the crowd. They propose to use probability thresholds for that purpose.
In contrast, CyLog takes the human-as-a-data-source approach in that we model each human as a rational data source and that we design data games and aggregations to obtain values with required properties.
- CrowdDB: CrowdDB provides an SQL-compatible language to handle queries that cannot be answered by machines only. They try to achieve the data independence and query optimitzation in the presence of the crowd processing.
Their CNULL and our open attributes are similar to each other.
- CrowdForge: A MapReduce-like framework/toolkit, being developed by CMU, to implement complex crowdsourcing applications based on the partition, map, and reduce abstractions. Compared to CyLog, CrowdForge gives us a higher-level abstraction to define the structure of crowdsourcing applications.
We think that CyLog can be used as an executable language into which the application definition by CrowdForge can be translated.
|
Publications/Talks
- Atsuyuki Morishima. CyLog/Crowd4U: A Case Study of a Computing Platform for Cybernetic Dataspaces (Invited Chapter).
Handbook of Human Computation, Springer, 2014. (to appear)(NEW!)
- Atsuyuki Morishima, Takanori Kawashima, Takashi Harada, Norihiko Uda, Ikki Ohmukai.
L-Crowd: A Library Crowdsourcing Project by LIS and CS Researchers in Japan (Invited Talk),
International Conference on Digital Libraries (ICDL2013), November 2013. (to appear)
(NEW!)
- Aoki Hideto, Atsuyuki Morishima. A Divide-and-Conquer Approach for Crowdsourced Data Enumerataion.
SocInfo 2013, November 2013. (to appear)(NEW!)
- Kenji Gonnokami, Atsuyuki Morishima, Hiroyuki Kitagawa. Condition-Task-Store: A Declarative Abstraction for Microtask-based Complex Crowd-sourcing.
DBCrowd 2013: 20-25, August 2013.(NEW!)
- Tomomi Mitsuishi, Atsuyuki Morishima, Norihide Shinagawa, Hideto Aoki. "Efficient Evaluation of Human-powered Joins with Crowdsourced Join Pre-filters." The 7th ACM International Conference on Ubiquitous Information Management and Communication (ACM ICUIMC2013), 6 pages, Kota Kinabalu, Malaysia, January 17-19, 2013.
- Atsuyuki Morishima. Declarative Data-centric Crowdsourcing. The 7th Korea-Japan Database Workshop 2012,(KJDB 2012) November 30 - December 2, 2012.
- Atsuyuki Morishima, Norihide Shinagawa, Tomomi Mitsuishi, Hideto Aoki, Shun Fukusumi. CyLog/Crowd4U: A Declarative Platform for Complex Data-centric Crowdsourcing.
PVLDB 5(12): 1918-1921 (2012)
- Shun Fukusumi, Atsuyuki Morishima, Norihide Shinagawa, Hiroyuki Kitagawa.
Applying DB Abstraction and Game Theory to Development of a GWAP for Extracting Structured Data from Microblogs
DBSJ Journal, Vol 11, No. 1, pp. 19-24, June 2012. (in Japanese)
- Tomomi Mitsuishi, Atsuyuki Morishima, Norihide Shinagawa, Hideto Aoki
Evaluation of a Crowdsourced Method for the Efficient Processing of Human-powered Joins
The third symposium on social computing (SoC 2012), 6 pages, Tokyo, June 2012. (in Japanese)
- Hideto Aoki, Atsuyuki Morishima, Norishide Shinagawa. A Cover-all Operation for Data Crowdsourcing.
DEIM Forum 2012, 7 pages, March 2012. (in Japanese)
- Shun Fukusumi, Atsuyuki Morishima, Norihide Shinagaawa. Data Extraction from Microblogs with a GWAP.
DEIM Forum 2012, 8 pages, March 2012. (in Japanese)
- Tomomi Mitsuishi, Atsuyuki Morishima, Norihide Shinagawa, Hideto Aoki. Efficient Evaluation of Human-powered Joins with Crowdsourcing.
DEIM Forum 2012, 6 pages, March 2012. (in Japanese)
- Atsuyuki Morishima, Norihide Shinagawa, Shoji Mochizuki. The Power of Integrated Abstraction for Data-centric Human/Machine Computations.
First International Workshop on Searching and Integrating New Web Data Sources (VLDS2011) Co-located with VLDB 2011, pp. 5-8, September, 2011. (pdf here. Slides here. A technical report (long version) will be available soon)
- Tomomi Mitsuishi, Norihide Shinagawa, Atsuyuki Morishima. Fusion of Human/Machine Computations: A Development Environment and Applications. Social Computing Symposium 2011, June 2011. (poster with demonstrations: poster in Japanese here)
- Tomomi Mitsuishi, Shoji Mochizuki, Atsuyuki Morishima. CySearch: Proposal of a System for the Blended Search of Human and Computer Information Sources, Proc. of the 73rd IPSJ Annual Conference, Vol. 1, pp. 683-684, March 2011. (in Japanse)
- Yui Yasunaga, Shoji Mochizuki, Atsuyuki Morishima. Proposal of a Method for Building Ontologies with GWAPs, Proc. of the 73rd IPSJ Annual Conference, Vol. 1, pp. 765-766, March 2011. (in Japanse)
- Atsuyuki Morishima. A Database Abstraction for Data-intensive Social Applications.
The 5th Korea-Japan Database Workshop 2010 (KJDB2010), May 28-29, 2010.
Jeju Province, Korea. (Invited Talk: Slides here)
- Noriaki Anzai, Atsuyuki Morishima. A Database Language for Collaborative Data Management by Computers and People. IPSJ Technical Report, 2009-DBS-149(12), pp. 1-8, Nov. 2009. (in Japanese)
|

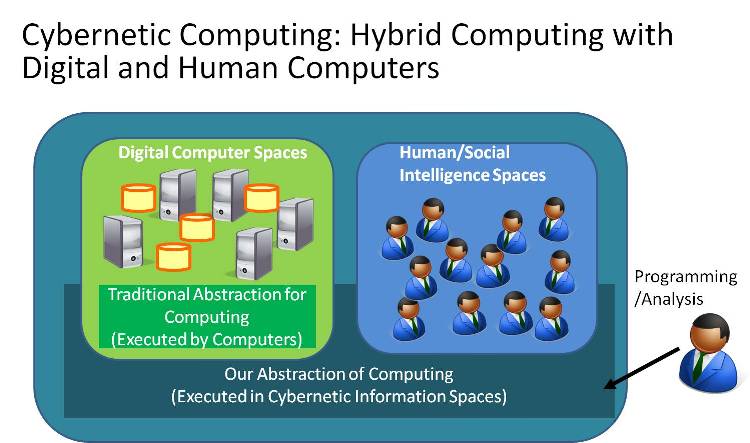 An important issue of the FusionCOMP project is to develop a programming language as an analyzable, executable, and integrated abstraction of data-centric human/machine computations.
The two main goals are:
An important issue of the FusionCOMP project is to develop a programming language as an analyzable, executable, and integrated abstraction of data-centric human/machine computations.
The two main goals are: